In english: How to create a C or C++ library (DLL) : common mistakes.
Il est fréquent de fournir une librairie (bibliothèque) pour permettre au client d'utiliser votre produit dans son logiciel. Par exemple, si vous fournissez un logiciel de calcul scientifique, le client aura peut-être besoin de lire les fichiers générés par votre logiciel ou bien intégrer certains calculs à son produit. Si vous vendez des sondes de dioxyde de carbone, vous fournissez sûrement une DLL (Dynamic Link Library) permettant de lire les mesures.
Peu importe dans quel langage est développé votre logiciel, fournir une interface en C est permet une intégration presque partout et une utilisation dans la plupart des langages.
Sous Windows, vous fournissez donc un fichier .dll contenant les fonctions utiles au client, un fichier .lib qui liste ces fonctions et indique comment les trouver dans la .dll et un fichier .h qui contient la signature des fonctions lisibles par le programmeur. Sous Linux, la DLL s'appelle .so et elle est fournie uniquement avec un fichier .h.
Faut-il fournir une interface en C ou en C++ ?
Si vous avez développé votre programme en C++ et que vos clients utilisent du C++, fournir une DLL pour ce même langage permet d'en simplifier l'utilisation pour le client car il bénéficiera des avantages des classes, des références, etc. C'est ce que fait Qt par exemple. L'inconvénient est qu'il faut compiler la librairie pour plusieurs compilateurs voire plusieurs versions d'un même compilateur : GCC, Clang, MSVC (Visual Studio 2015, 2022, etc), etc.
La librairie standard C++ peut aussi changer entre les versions d'un même compilateur : entre deux versions de Visual Studio, par exemple std::string peut changer et provoquer des plantages difficiles à comprendre.
Une librairie C++ a certains avantages, mais a aussi un coût. Une solution est de rendre la bibliothèque open source pour que le client puisse la recompiler ; une autre solution est de développer une interface C++ header-only (uniquement dans le .h) qui cache l'interface C.
Éviter des erreurs fréquentes
malloc et free ou bien new et delete doivent être fait dans la même entité (programme ou DLL). Considérez la fonction suivante :
DLL_EXPORT char* GetProjectName(Project_t id);
Ici GetProjectName renvoie une chaine de caractères qui a été allouée par la DLL. Si le compilateur du client est différent du compilateur qui a produit la DLL, désallouer la chaine de caractères avec free peut provoquer un plantage car l'implémentation de l'allocateur peut être différente. Par exemple en debug, malloc et free peuvent être instrumentés pour détecter des problèmes.
La solution classique est la suivante :
DLL_EXPORT void GetProjectName(Project_t id, char* name);
Dans ce cas le client doit allouer un tableau et GetProjectName va copier la chaine. Il faut fournir au client la taille maximum possible ou une fonction GetProjectNameLength. Un alternative est de définir un type qui contient la chaine :
typedef struct MyString_ {
const char * const str;
} MyString_t;
Et des fonctions pour manipuler MyString_t :
DLL_EXPORT MyString_t* CreateMyString(const str* ms); DLL_EXPORT void DeleteMyString(MyString_t* ms); DLL_EXPORT MyString_t* GetProjectName(Project_t id);
Les fonctions CreateMyString et GetProjectName font un malloc et la fonction DeleteMyString, un free. C'est donc la DLL qui se charge à la fois de l'allocation et de la libération de la mémoire.
On réduit aussi les erreurs car l'utilisateur n'a plus besoin de se soucier d'allouer la bonne taille. Les consts interdisent la modification de str par l'utilisateur pour éviter que DeleteMyString se retrouve à appeler free sur des données allouées par l'utilisateur.
Clarifier l'interface. Et les types sont là pour ça. On considère la fonction suivante :
DLL_EXPORT int GetCurrentProjectId(); DLL_EXPORT void RemoveFile(int projectId, int fileId);
Ici ce code peut être rendu beaucoup plus clair avec des types
typedef int ProjectId_t; typedef int FileId_t; DLL_EXPORT ProjectId_t GetCurrentProjectId(); DLL_EXPORT void RemoveFile(ProjectId_t projectId, FileId_t fileId);
Malheureusement, le compilateur n'émettra même pas un warning si l'utilisateur place un ProjectId_t au lieu d'un FileId_t, mais le code est quand même plus lisible.
Const correctness. Déclarer les pointeurs ou références const dès que possible.
DLL_EXPORT char* SetProjectName(Project_t id, const char* str);
Ici, str est const char*, c'est indispensable si l'utilisateur veut passer une chaine de caractère constante. Son code ne pourra pas respecter la const correctness si vous ne le faites pas.
Pas plus de 4 paramètres pour vos fonctions. Utiliser une structure si la fonction a trop d'entrées. Pour retourner plusieurs paramètres utilisez des structures. N'utilisez surtout pas de tableaux pour renvoyer des données de natures différentes. Par exemple renvoyer un tableau contenant [x y z] peut être dangereux car l'utilisateur risque de se tromper d'ordre. En C++, évitez les std::pair qui ont ce défaut aussi.
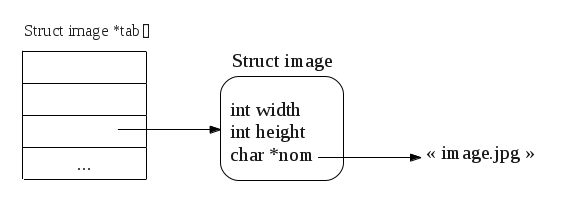
Utilisez des pointeurs opaques pour identifier les instances de votre lib, cela permet de cacher les données stockées. En C++, le patron PIMPL sert à ça. Dans les exemples précédents, j'ai utilisé des entiers (par exemple Project_t) ce qui est moins efficace car il faut une map qui stocke la correspondance mais c'est parfois plus facile à gérer dans le logiciel du client.
Bien documenter le format des données, les types et les unités GetPressure, GetTemperature, GetDistance ne veulent rien dire si on ne précise pas si ce sont des bars, des N/m², des °C, °F, des mètres ou des mm.
Le plus important : la lib est l'interface entre vous et le client. La documentation et le nom des fonctions doit utiliser les termes du client pas un jargon interne !
En conclusion, demandez-vous ce que le client va comprendre de votre interface et quelles erreurs il va faire. Facilitez-lui la tâche en rendant les erreurs difficiles voire impossibles.